Over the past five years, we have worked with dozens of discrete and process manufacturers across automotive, food & beverage, industrial equipment, and electronics. Almost every engagement starts the same way: a production director pulls up a spreadsheet and says, “this is the best picture we have of what happened on the line last week.”
The machines generating that data are often connected — PLCs, SCADA systems, CNC controllers, and quality sensors produce enormous volumes of time-series data every shift. The problem is almost never a lack of data. It is that the data lives in silos: trapped in historians on isolated OT networks, exported manually into ERP systems, or simply discarded after a 30-day rolling buffer fills up.
A unified data pipeline changes that calculus. When shop floor telemetry flows continuously into a governed cloud environment, manufacturers gain the ability to detect anomalies in real time, build predictive maintenance models on years of historical context, and tie quality outcomes back to specific machine parameters, operators, and raw material lots. The competitive advantage is substantial. The architecture, however, requires deliberate design.
Why most manufacturers' data strategies fail at the edge
Enterprise technology vendors love to show the cloud tier. The dashboards, the machine learning notebooks, the executive KPI views — all of it looks impressive in a sales presentation. What those presentations quietly skip is the hard part: getting reliable, contextualized data off the plant floor in the first place.
The failure modes we encounter most often are predictable. Manufacturers attempt to connect legacy PLCs using protocols they were not designed to support at scale, generating an unstable fire-hose of raw tag values with no engineering context. Or they deploy a point-to-point integration between a single machine and a cloud service, declare success, and discover six months later that scaling that approach to 200 assets is not financially viable. Or, most commonly, they build a beautiful data lake that production engineers do not trust because the values disagree with what they see on the HMI.
The foundation of a successful pipeline is not a technology choice. It is an architecture decision: where does data get shaped, contextualized, and validated before it travels further upstream? Getting this wrong means every downstream system inherits the mess.
The four-layer architecture that actually works
Regardless of your cloud provider, historian vendor, or ERP platform, a durable manufacturing data pipeline shares a common logical structure. Think of it as four distinct layers, each with a clear responsibility boundary.
The critical design principle here is the separation between operational technology (OT) and information technology (IT) concerns. Layers 1 and 2 live in the plant. They must operate even when WAN connectivity is degraded. Layers 3 and 4 live in the cloud or on enterprise IT infrastructure, and they consume a reliable, normalized stream rather than talking directly to field devices.
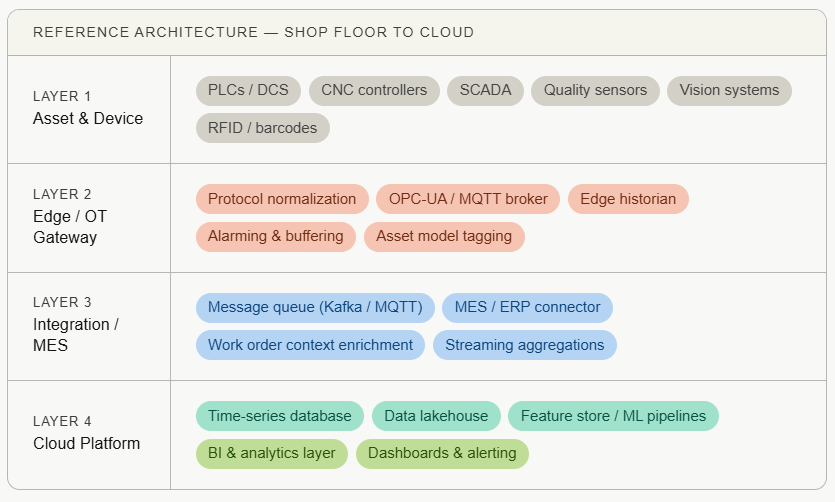
Connectivity: getting data off the machine
The asset layer is where the physics of manufacturing lives: spindle speeds, temperatures, pressures, vibration, cycle counts, and reject flags. Your job at this layer is to read that data reliably without destabilizing the control systems that depend on it.
Protocol landscape
Modern connectivity for manufacturing assets has largely converged on two standards. OPC Unified Architecture (OPC-UA) is the dominant choice for PLCs, DCS systems, and SCADA servers — it provides a rich information model, built-in security, and publish-subscribe semantics that dramatically reduce polling overhead. MQTT has become the de facto lightweight protocol for constrained devices, edge sensors, and IoT hardware where OPC-UA’s overhead is impractical.
In practice, most plant floors contain neither. You will encounter Modbus TCP/RTU on legacy equipment from the 1990s, proprietary protocols from major automation vendors (Siemens S7, Allen-Bradley’s EtherNet/IP, Fanuc FOCAS), and occasionally PROFINET or EtherCAT on newer production cells. An edge gateway layer must speak all of these natively and normalize them to a unified OPC-UA or MQTT output — this is non-negotiable if you want a maintainable system.
Data frequency and volume planning
One of the most common mistakes we see is over-collecting at the source without a clear retention and downsampling strategy. A single PLC may expose thousands of tags at 100ms resolution. Collecting everything at full fidelity into a cloud database is technically possible but economically catastrophic at scale. Before wiring up your first data source, answer three questions:
Which tags drive a decision or model? Collect these at high frequency. Everything else can be aggregated at the edge.
What is the minimum fidelity needed to detect the anomaly you care about? Many fault signatures are visible at 1-second resolution, not 100ms.
What is your long-term retention requirement? Regulatory, quality audit, and model training needs differ significantly — architect your storage tiers accordingly.
Edge computing and the OT/IT boundary
The edge layer is where the most consequential architectural decisions get made, and where the most costly mistakes happen. Its job is to serve as a hardened buffer and normalization layer between the deterministic world of industrial control systems and the probabilistic world of cloud connectivity.
What belongs at the edge
Edge processing should handle anything where latency to the cloud creates unacceptable risk: closed-loop alarming, line stop conditions, and safety interlocks should never depend on a round trip through the internet. Beyond safety, the edge is the right place to perform asset model tagging — mapping raw PLC addresses to human-readable, contextual names that travel with the data upstream. A tag value of Line3.Cell2.Spindle.ActualSpeed is exponentially more useful than register address D14023 when a data scientist encounters it six months later.
Edge historians serve a critical resilience function. When WAN connectivity is interrupted — and it will be — the edge layer must buffer telemetry locally and replay it in order when connectivity resumes. A cloud-first architecture without local buffering creates systematic data gaps at exactly the moments you most want visibility: during network maintenance windows, brownouts, and plant shutdowns.
The OT/IT security boundary
The edge gateway is the crossing point between OT and IT networks, and it must be treated as a security boundary, not merely a network junction. Data flows one direction: northbound from OT to IT. Any southbound traffic — cloud services pushing configurations, firmware updates, or commands to production assets — must go through explicit, audited change management processes with OT engineering sign-off.
In practice, this means deploying the edge layer in a demilitarized zone (DMZ) with strict firewall rules permitting only outbound MQTT or OPC-UA connections to the integration layer. Remote access to edge infrastructure should use jump servers or zero-trust network access products rather than open VPN endpoints.
Cloud ingestion, transformation, and storage
Once data crosses the OT/IT boundary in a normalized, contextualized form, the cloud platform tier handles the work that enterprise analytics demands: durable storage at scale, enrichment with business context, and presentation to consuming systems.
Ingestion and streaming
A message broker sits at the top of the cloud ingestion path, decoupling producers from consumers and providing the durability guarantees needed when downstream systems are temporarily unavailable. Apache Kafka is the dominant choice for high-throughput industrial workloads — it handles millions of events per second and provides configurable retention that lets multiple consumers read the same stream at their own pace. For manufacturers not ready to operate Kafka clusters, managed alternatives from Azure (Event Hubs), AWS (Kinesis), and Google Cloud (Pub/Sub) offer comparable semantics with significantly lower operational overhead.
Time-series storage
Manufacturing telemetry is time-series data, and it should live in a purpose-built time-series database rather than a relational system. The query patterns — “give me spindle speed for machine 7 between 06:00 and 14:00 on Tuesday” — require time-indexed retrieval with downsampling functions that row-oriented databases handle poorly at scale. Purpose-built options like InfluxDB, TimescaleDB, and cloud-native offerings (Azure Data Explorer, AWS Timestream) deliver orders-of-magnitude better query performance for these workloads while supporting native data compression that reduces storage costs on long time horizons.
The lakehouse for historical analysis
Time-series databases are optimized for operational queries but less suited for the large historical scans needed to train machine learning models or perform root cause analysis across years of data. A lakehouse architecture — cloud object storage (S3, ADLS, GCS) organized with a table format like Delta Lake or Apache Iceberg — provides the complementary capability. Raw telemetry is written to the lakehouse in Parquet format alongside enriched, joined datasets that include work order context, material lot traceability, and quality inspection results.
This separation of concerns between operational time-series storage and analytical lakehouse storage is one of the most important structural choices in the architecture. Attempting to serve both use cases from a single system is a common failure mode that results in either poor query performance for operations or prohibitive cost for analytics.
Governance, security, and compliance
A data pipeline without governance is a liability masquerading as an asset. As manufacturing data flows into enterprise cloud environments, it becomes subject to a complex matrix of requirements: equipment supplier confidentiality agreements that restrict how machine data can be shared, quality regulatory frameworks (FDA 21 CFR Part 11, ISO/TS 16949) that mandate audit trails, and cybersecurity standards like IEC 62443 that govern OT network protections.
Data catalog and lineage
Every dataset that flows through the pipeline should be catalogued with metadata describing its source asset, the transformations applied, and its downstream consumers. When a quality engineer asks why an OEE figure disagrees with the historian value, lineage metadata makes the answer findable in minutes rather than days. Data catalog tooling (Collibra, Alation, or open-source alternatives like Apache Atlas) should be part of the architecture from the start — retrofitting it is significantly more expensive.
Access control and data classification
Not all manufacturing data carries the same sensitivity. Machine cycle counts are generally shareable across the organization. Tooling parameters on a precision machined component may be subject to a supplier non-disclosure agreement. Personally identifiable data tied to operator log-ins carries regulatory obligations in most jurisdictions. Implementing role-based access control at the dataset level — not just at the platform level — is essential for enterprises operating in multiple business units or regions.
Phasing your rollout for realistic ROI
The architecture described in this guide can feel overwhelming when viewed as a single program. The manufacturers we have seen succeed treat it as a series of bounded, value-generating phases rather than a single transformation initiative.
Phase 1: Connect and observe (months 1–6)
Select a single production line or work cell — ideally one with a clear pain point such as excessive unplanned downtime or high scrap rates — and implement the full stack from asset connectivity through a basic cloud dashboard. The goal is not to solve the problem yet. It is to establish that data flows reliably, that the asset model is correct, and that production engineers trust what they see on screen. This phase should be budgeted and scoped conservatively: its value is proving the architecture, not delivering business outcomes.
Phase 2: Expand and enrich (months 6–18)
Roll the proven architecture across additional assets and begin enriching telemetry with business context from MES and ERP systems. Work order numbers, material lot codes, shift assignments, and customer specifications should join the data stream at this layer. This is also the phase where you build the lakehouse foundation and begin populating the historical dataset that machine learning models will require later. Target use cases: OEE dashboards, quality correlation analysis, and shift-to-shift performance comparisons.
Phase 3: Predict and prescribe (months 18+)
With 12 or more months of governed, contextualized historical data, predictive use cases become viable. Anomaly detection models trained on asset telemetry can surface early fault signatures before they become unplanned downtime events. Quality prediction models can identify process conditions that correlate with out-of-spec product before the inspection step. These initiatives require data science capability and a mature MLOps practice — investment that is premature in Phase 1 but essential for sustaining competitive advantage in Phase 3.
Getting started
The single highest-leverage action most manufacturers can take today is conducting a connectivity audit of their highest-priority assets: what protocols are exposed, what data is already flowing into a historian, and where the OT/IT boundary currently sits. That audit typically reveals both the quick wins — assets already producing OPC-UA data that can be connected with minimal effort — and the hard constraints that will shape the architecture.
Building a unified data pipeline is not a technology project. It is an organizational capability. The technical architecture matters enormously, but it will deliver nothing without the operational ownership, governance processes, and cross-functional collaboration between IT, OT, and analytics teams that make the data trustworthy enough to act on.
The manufacturers who get this right do not just report better. They respond faster, waste less, and build the institutional knowledge that turns raw production data into genuine competitive advantage.