Every manufacturer sitting on years of production data has faced some version of the same question: where does all of this actually live, and what can we do with it? The answer used to be simple — you bought a database, you stored your numbers, you ran your reports. But as manufacturing operations have grown more instrumented, more connected, and more analytically ambitious, the architecture question has gotten considerably harder.
Today, three competing paradigms dominate the conversation: the data warehouse, the data lake, and the increasingly popular lakehouse. Each has genuine strengths, and each carries real tradeoffs. The wrong choice doesn’t just waste capital — it shapes what questions you can ask about your operation for years to come. Getting it right requires understanding not just what each architecture does, but what kind of manufacturing analytics organization you are, and what you’re trying to become.
The Data Warehouse: Structured Precision for Known Questions
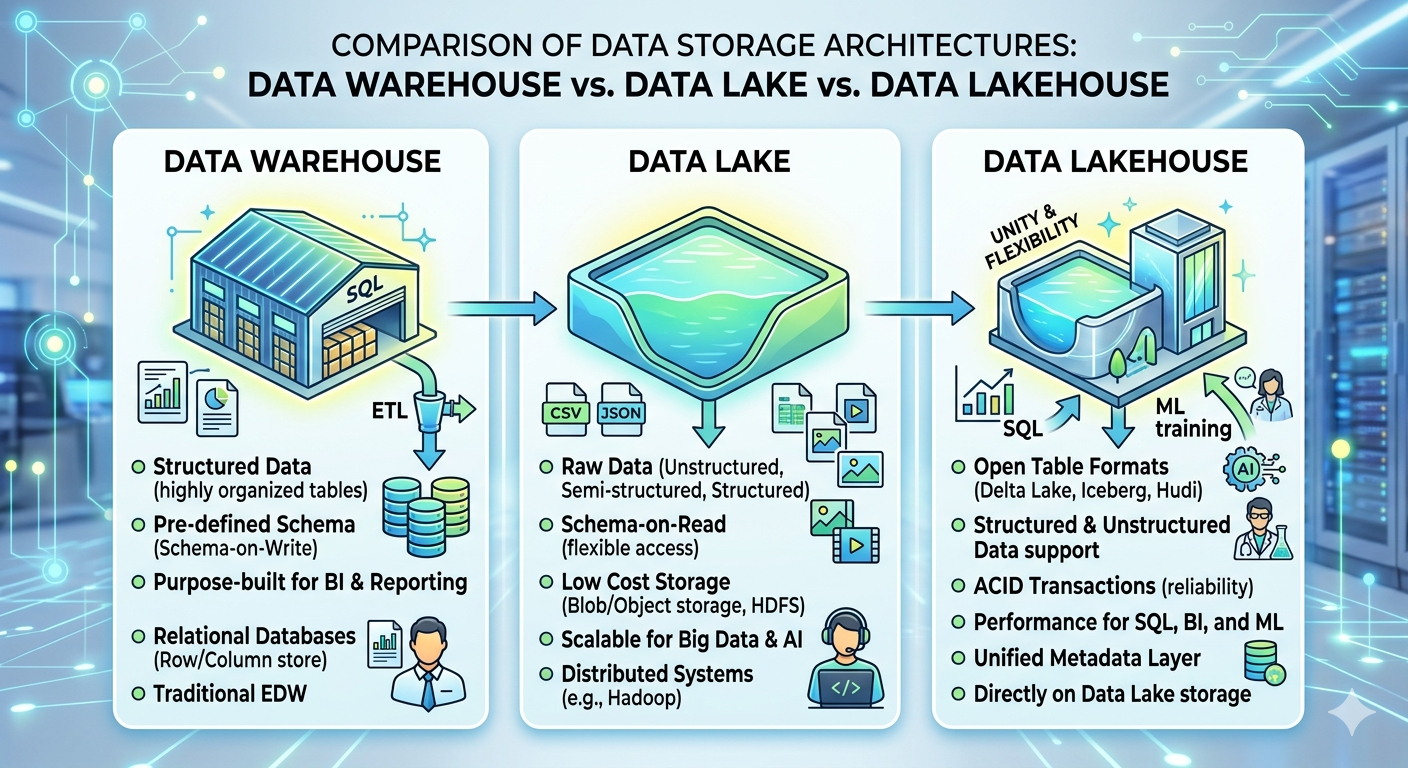
The data warehouse has been the backbone of enterprise analytics for decades, and in manufacturing it earned that position honestly. A warehouse is a centralized repository of structured, transformed data — cleaned, modeled, and organized specifically to answer the questions the business knows it needs to ask. Think OEE reports, production yield summaries, quality rejection rates by line, inventory turns, supplier on-time delivery metrics.
The warehouse excels when the questions are well-defined and the data sources are finite. If your plant controller needs a daily report on first-pass yield across five lines, a properly built warehouse delivers that fast, reliably, and in a format the ERP system, your BI dashboards, and your finance team all understand. The data has been transformed through an ETL (extract, transform, load) process before it lands in the warehouse, which means it’s already been cleaned, validated, and structured according to agreed-upon business rules.
For manufacturers whose analytics needs center on operational reporting — the classic KPI dashboards, variance reporting against standard costs, shift-level throughput summaries — the warehouse remains a highly defensible choice. The query performance is predictable. The governance model is mature. Your reporting teams can operate without a data science team looking over their shoulder.
The tradeoff is rigidity. A warehouse is built around a schema — a predefined structure that determines how data is organized and related. When a new question arises that the schema didn’t anticipate, someone has to go back and rebuild part of the pipeline. When a new data source appears — say, a new SCADA system for a freshly acquired facility, or a vision inspection system generating image-level defect metadata — integrating it requires significant upfront engineering work. The warehouse can’t accept raw data and figure it out later. Everything must be defined before it lands.
For manufacturers running stable, mature operations with predictable reporting needs, this tradeoff is entirely acceptable. For operations undergoing rapid technology adoption, M&A activity, or digital transformation, the schema-first architecture starts to become a bottleneck.
The Data Lake: Raw Flexibility at Scale
The data lake emerged as the answer to a real problem: manufacturing operations generate an enormous and growing volume of data in formats that weren’t designed to slot neatly into relational tables. Sensor readings from PLCs. Image files from machine vision systems. Audio signatures from vibration monitoring. Log files from edge devices. JSON payloads from IoT platforms. Maintenance tickets from CMMS systems.
A data lake stores all of this data in its raw, native format at massive scale. Nothing gets thrown away. Nothing gets transformed before storage. The lake accepts everything — structured, semi-structured, and unstructured — and stores it cheaply in a cloud object store like Amazon S3, Azure Data Lake Storage, or Google Cloud Storage. The theory is sound: store everything now, figure out what to do with it later. Schema is applied at read time, not write time.
The promise of the data lake resonated deeply in manufacturing because it aligned with a real anxiety: the fear of not having data when you later realize you needed it. If you’ve ever tried to build a predictive maintenance model and discovered that the sensor data from three years ago was never retained, you understand why that anxiety is rational.
But the practice of data lakes in manufacturing has generated a well-documented cautionary tale. Without rigorous governance, lakes become swamps — repositories of data that nobody fully understands, with no reliable catalog, no quality guarantees, and no clear ownership. Data scientists spend the majority of their time hunting for usable data rather than building models. The “store everything” philosophy, when it’s not accompanied by disciplined metadata management and data quality processes, produces enormous storage bills and very little analytical output.
The lake is also architecturally separated from the high-performance query engines that make BI tools fast and interactive. Running ad-hoc SQL queries against raw Parquet files in a lake is possible, but it’s not the experience that plant managers and operations teams expect when they open a dashboard. The lake was never designed to be the last mile for operational reporting.
For manufacturers with large-scale data science programs, active machine learning initiatives, and the engineering resources to govern a lake properly, the architecture has real merit — particularly as a landing zone and long-term archive. For most mid-market manufacturers, it has proven to be an overextension.
The Lakehouse: Bridging the Gap
The lakehouse is the architecture the industry arrived at after a decade of watching warehouses struggle with flexibility and lakes struggle with governance. The term was formalized by Databricks but the concept has since been adopted broadly, and it describes a system that stores data in open formats in cloud object storage — like a lake — while adding a transactional metadata layer that enables the reliability, performance, and query characteristics of a warehouse.
The enabling technologies are open table formats: Apache Iceberg, Delta Lake, and Apache Hudi. These formats sit on top of the raw storage layer and give it capabilities it previously lacked: ACID transactions (meaning writes are atomic and consistent), time-travel (the ability to query historical versions of a table), schema enforcement with the ability to evolve schemas over time, and query performance optimization through file compaction and indexing.
In practice, what this means for a manufacturing analytics team is significant. You can ingest raw sensor data, production event streams, and quality inspection records into the same storage layer without having to transform everything upfront. You can run SQL queries against that data at performance levels that support BI dashboards, not just batch data science workflows. You can add a new data source — say, a new generation of CNC machines with different data structures than your legacy equipment — without redesigning your schema from scratch. And you retain the full history of the data for the audit trails that regulated manufacturers in aerospace, medical devices, and food and beverage cannot do without.
The lakehouse also enables what is increasingly the dominant pattern in manufacturing analytics: a unified architecture that serves both operational BI and advanced analytics from the same data layer. Machine learning engineers building predictive maintenance models and plant controllers pulling daily OEE reports are working from the same underlying data, with the same quality guarantees, rather than maintaining parallel data pipelines to separate systems.
The tradeoff is complexity and maturity. Lakehouse implementations require more sophisticated engineering than a traditional warehouse setup. The tooling ecosystem — Databricks, Apache Spark, dbt, the cloud-native variants from AWS, Azure, and GCP — is powerful but not simple. Manufacturers without experienced data engineers on staff or strong partnerships with implementation specialists can find lakehouse projects stalling in technical complexity before they deliver business value.
The Manufacturing Context: What Actually Drives the Decision
Abstract architecture comparisons are useful only up to a point. What matters in manufacturing is how these choices interact with the specific operational realities of the plant floor.
Data volume and velocity are the first considerations. A facility running a dozen CNC machines with daily production reports has fundamentally different requirements than a continuous process operation generating millions of sensor readings per hour from hundreds of instrumented assets. High-velocity, high-volume environments — chemical plants, semiconductor fabs, automotive stamping operations — put serious pressure on traditional warehouse architectures and push toward lake or lakehouse approaches that can absorb raw data streams without the ETL bottleneck.
Use case diversity is the second factor. If your analytics roadmap consists entirely of operational dashboards and financial reporting, a well-governed warehouse is probably sufficient and will deliver faster time-to-value. If you’re actively building predictive quality models, running statistical process control at scale, or developing equipment anomaly detection programs, the flexibility and raw data access of a lakehouse is worth the added complexity. The question to ask honestly is: what does the next three years of analytics look like, not just the next quarter?
Existing technology investments matter more than vendors typically acknowledge. Manufacturers who have invested heavily in SAP, Oracle, or Infor ERP ecosystems often find that warehouse architectures integrating with those systems through standard connectors are significantly easier to implement than greenfield lakehouse projects. The cost of ripping out established data pipelines is real and often underestimated in architecture discussions.
Team capability is frequently the deciding variable. The lakehouse is theoretically superior for a wide range of manufacturing analytics workloads, but “theoretically superior” doesn’t help if your team doesn’t have the Spark experience, the dbt knowledge, or the cloud platform expertise to build and maintain it. An architecture is only as good as the team’s ability to operate it in production. Many manufacturers have found that starting with a well-engineered modern cloud warehouse — Snowflake, BigQuery, Azure Synapse — delivers 80% of the capability at a fraction of the implementation risk, with a credible path to a lakehouse architecture as the team matures.
A Practical Framework for the Decision
Rather than advocating for any single architecture, the right approach is to map your current state against a few defining questions.
If your primary analytics consumers are operational and financial stakeholders who need reliable, fast, governed reporting against a stable set of KPIs — and your data sources are predominantly structured (ERP transactions, MES records, quality system outputs) — a cloud data warehouse is likely your most practical starting point. Prioritize governance, model your data well, and build the reporting capability your organization actually uses.
If you are running an advanced analytics program with data scientists, have machine learning models in production or near-production, and are dealing with large volumes of heterogeneous data including sensor streams, unstructured process data, and image or audio inputs — the lakehouse architecture is worth the investment. Build the governance processes alongside the technology, not after.
If you are somewhere in between — a growing analytics capability, a mix of BI and early-stage data science, a team that is building its skills — consider a warehouse as the operational reporting backbone with a data lake as a landing zone and experimentation layer. Many manufacturers operate effectively in this hybrid model, with a deliberate migration path toward a unified lakehouse as both capability and need mature.
The Integration Layer That Most Manufacturers Overlook
Whichever architecture you choose, the challenge that consistently determines success or failure in manufacturing analytics isn’t the storage layer — it’s the integration layer between the plant floor and the data platform. OPC-UA, MQTT, Historian systems, SCADA outputs, MES APIs, ERP extracts: the plumbing that moves data from machines and control systems into your analytical infrastructure is where most projects actually break down.
A beautifully architected lakehouse sitting on top of a chaotic, inconsistent data ingestion layer will deliver chaotic, inconsistent analytics. The architecture decision and the data integration strategy have to be made together, not sequentially. This is where the difference between a thoughtful implementation and a shelf-ware analytics project is usually determined.
Closing Perspective
The data warehouse versus data lake versus lakehouse debate is, at its core, a question about what kind of manufacturing analytics organization you are building. Each architecture reflects a different set of assumptions about data volumes, use case diversity, team capability, and organizational maturity.
The warehouse is a precision instrument for known questions. The lake is a flexible archive for unknown futures. The lakehouse is an attempt to have both — and largely succeeds, at a cost in complexity. None of these is universally correct, and any consultant or vendor who tells you otherwise is selling architecture rather than solving problems.
The manufacturers who get the most value from their data investments are the ones who make architecture decisions grounded in operational reality, build strong data governance from day one rather than retrofitting it later, and treat the shop floor integration layer with as much rigor as the analytical platform itself. The technology choices follow from those disciplines, not the other way around.