Every few years, Statistical Process Control gets rediscovered. A new generation of quality engineers finds Shewhart’s work, plants control charts on the shop floor, and declares victory. Then the charts go stale. Operators stop trusting them. Leadership loses interest. And the cycle repeats.
This isn’t a technology problem. It’s a discipline problem — and understanding the difference is the first step toward building an SPC program that actually holds.
What SPC Is (And What It Isn't)
Walter Shewhart developed the foundational ideas of SPC at Bell Laboratories in the 1920s. The core insight was deceptively simple: not all variation in a process is the same. Some variation is inherent to the process — random, expected, the natural noise of a system operating as designed. Shewhart called this common cause variation. Other variation is attributable to something specific and identifiable — a worn tool, a bad batch of material, an undertrained operator. He called this special cause variation.
The control chart is a mechanism for distinguishing between the two in real time. Plot your process data over time, establish control limits based on the process’s own historical behavior, and watch for signals that suggest something outside the normal system is at work.
That’s it. That’s the intellectual core.
Where manufacturers go wrong is in confusing the tool with the discipline. A control chart on a screen is not SPC. SPC is the organizational commitment to distinguish between types of variation, respond differently to each, and — critically — not tamper with a process that is in control just because a single point lands near a limit.
That last point deserves emphasis. Over-adjustment is one of the costliest mistakes in manufacturing, and control charts exist partly as a defense against it. When operators adjust a process every time a measurement moves — without evidence of a true special cause — they introduce additional variation rather than reducing it. W. Edwards Deming spent decades arguing this point. Manufacturers are still fighting the same battle.
The Six Charts That Actually Matter
Most SPC implementations lean on a handful of chart types. Understanding when each is appropriate is where the practice gets substantive.
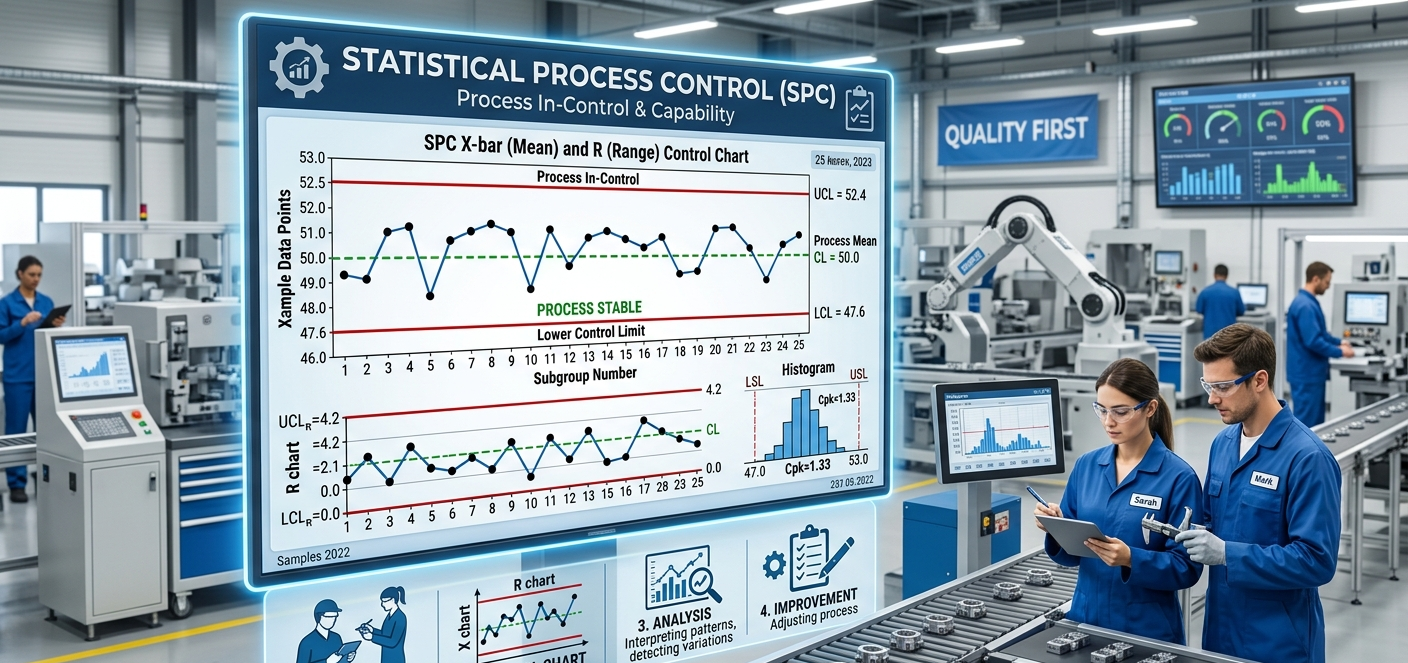
X-bar and R charts remain the workhorses of continuous data monitoring. You collect subgroups — small samples taken at intervals — plot the subgroup mean on the X-bar chart and the subgroup range on the R chart. The R chart must be in control before the X-bar chart is interpretable; a process with unstable variation cannot have meaningful mean-monitoring. These charts assume normality within subgroups and work best when subgroup sizes are between 2 and 10.
Individuals and Moving Range (I-MR) charts handle the common manufacturing reality where subgroups don’t make sense — one measurement per batch, one reading per cycle, one chemical assay per lot. The moving range between consecutive measurements stands in for the within-subgroup variation that would otherwise inform control limits. These charts are more sensitive to non-normality than X-bar/R charts, and practitioners should check distributional assumptions before trusting the limits.
P and NP charts shift into the world of attribute data — specifically proportion or count of nonconforming units. P charts accommodate varying subgroup sizes; NP charts require constant subgroup sizes. Both assume a binomial distribution, which means each unit is either conforming or it isn’t, and units are independent. That independence assumption breaks down more often than people expect in manufacturing — particularly with autocorrelated processes or clustered defects.
C and U charts handle count of nonconformities rather than nonconforming units — the number of scratches on a panel, the number of solder defects on a board. C charts require constant inspection area or opportunity; U charts handle varying opportunity sizes. Both assume a Poisson distribution, and both inherit the independence assumption problem.
The selection among these isn’t arbitrary. Getting it wrong produces misleading control limits and incorrect signals — the statistical equivalent of watching the wrong instrument.
Establishing Meaningful Control Limits
The most common implementation mistake is treating control limits as specifications. They are not. Control limits are calculated from process data to describe how the process actually behaves. Specification limits describe what the customer requires. These are independent quantities, and confusing them corrupts the analysis entirely.
Control limits are conventionally set at three standard deviations from the process mean — not because three is a magic number, but because Shewhart’s empirical work and subsequent economic analysis found it a reasonable balance between sensitivity to real signals and tolerance for false alarms. At three-sigma limits, a process in statistical control will produce a false alarm roughly 0.27% of the time — about once every 370 points on average.
Establishing Phase I control limits — the baseline from which limits are derived — requires a stable reference period. In practice, this means collecting 20 to 25 subgroups (or 100 or more individual measurements for I-MR charts) from a period when the process is believed to be operating normally, examining those data for special causes, removing confirmed special-cause points with documented rationale, and recalculating until a stable baseline emerges.
This Phase I work is where most rapid implementations collapse. Teams grab whatever data is available, compute limits, and go live. The resulting limits reflect the process’s history of chaos as much as its normal behavior. When those limits are then used for real-time monitoring in Phase II, they’re too wide to detect meaningful signals — or too narrow if the baseline period was unusually clean. Neither serves the purpose.
The Eight Tests for Special Causes
A single point beyond the three-sigma control limits is the most obvious signal of a special cause. But Shewhart’s original rules, extended by the Western Electric Company and later refined by Lloyd Nelson and others, describe additional patterns in the data that suggest non-random behavior:
The Western Electric rules include: one point beyond three sigma; two of three consecutive points beyond two sigma on the same side; four of five consecutive points beyond one sigma on the same side; and eight consecutive points on the same side of the centerline. Nelson’s extensions add patterns like six consecutive points trending in one direction, fifteen consecutive points within one sigma of the centerline (suggesting stratified sampling or a process that has narrowed), and fourteen consecutive points alternating up and down.
Each of these patterns has a specific probability of occurring by chance in a stable process. Running all eight rules simultaneously inflates the false alarm rate significantly — the probability of at least one false alarm in a given sample rises with each additional rule applied. Practitioners should choose the tests appropriate to the known failure modes of their process rather than applying all tests universally.
Understanding what each pattern implies mechanistically matters. A sustained shift often suggests a process input that changed and stayed changed — a new material lot, a replaced component. A trend suggests gradual degradation — tool wear, thermal drift. Stratification suggests the data is being drawn from multiple process streams that should be separated. Knowing the likely physical causes shapes the investigation response.
SPC in the Context of Modern Manufacturing Data Infrastructure
The rise of industrial IoT, time-series historians, and edge computing has created both opportunity and complexity for SPC programs.
The opportunity is obvious: sensors can now generate data at rates and granularities that manual sampling could never approach. A machine that previously provided a shift-average measurement can now produce a measurement every 100 milliseconds. SPC applied at this resolution can detect process shifts in minutes rather than hours.
The complexity is less discussed. High-frequency process data almost always exhibits autocorrelation — successive measurements are not independent because the physical process has inertia. A mold temperature that rises slightly will still be elevated on the next measurement. A cutting fluid concentration that drifts will continue drifting. Standard control charts assume independence between observations. Applied to autocorrelated data, they produce dramatically elevated false alarm rates that erode operator trust and make charts meaningless.
Addressing autocorrelation in high-frequency SPC requires either time-aggregation to a sampling interval where independence is reasonable, or the use of ARIMA-based control charts that model and remove the autocorrelation structure before monitoring residuals. Neither approach is standard in most out-of-the-box SPC software, which means the responsibility falls to the implementation team.
A related challenge is multivariate process control. Modern manufacturing processes are characterized by many interacting parameters — temperature, pressure, humidity, line speed, material properties — and monitoring each independently misses the relationships between them. A temperature and pressure that are individually within limits may still represent an unusual combination. Hotelling’s T² statistic and related multivariate control charts address this, but they demand more statistical sophistication and make actionable diagnosis considerably harder. When a multivariate chart signals, it tells you something is unusual about the combination of variables — it doesn’t immediately tell you which variable to investigate.
The practical implication for manufacturers building data infrastructure: SPC is not a plug-in. It requires deliberate decisions about sampling strategy, variable selection, autocorrelation handling, and how process data flows from historian to monitoring to response. These decisions should happen before the first chart is configured, not after the first false alarm erodes credibility.
Process Capability: The Companion Discipline
SPC tells you whether a process is in statistical control — whether it’s behaving consistently. It says nothing about whether that consistent behavior is good enough. That question belongs to process capability analysis.
The capability indices Cp and Cpk are the standard vocabulary here. Cp measures the ratio of specification width to process spread (six sigma), describing what the process could achieve if it were perfectly centered. Cpk accounts for actual centering, describing what the process does achieve. A process with Cp of 1.5 and Cpk of 0.8 has adequate potential but is running significantly off-center — a centering problem, not a capability problem.
The industry benchmark of Cpk ≥ 1.33 (four-sigma performance, roughly 63 defects per million) is widely cited; high-reliability industries like automotive and aerospace commonly require Cpk ≥ 1.67. These thresholds assume normality. For non-normal processes — which are common in manufacturing when measurements are bounded, skewed, or multimodal — alternative approaches using percentile-based indices or distribution fitting are necessary to avoid dramatically overestimating capability.
A critical sequencing point: capability analysis only makes sense for a process in statistical control. Calculating Cpk for an out-of-control process produces a number that describes a mixture of the stable process behavior and whatever special causes are active. The number is not interpretable, and decisions made from it are unreliable. The correct sequence is always: achieve control first, then assess capability.
Building a Program That Sustains
The technical elements of SPC are well-documented. The organizational elements are where programs succeed or fail.
Response protocols must be defined before charts go live. A control chart that signals without a corresponding action plan teaches operators that signals don’t matter. Define in advance who is responsible for investigating each type of signal, what the initial response steps are, how investigations are documented, and how confirmed special causes are addressed at the root-cause level. Without this infrastructure, control charts become wallpaper.
Operator involvement is not optional. SPC programs driven entirely by quality engineers and monitored from a central dashboard frequently fail because the people closest to the process have no stake in the system. Operators who understand why they’re monitoring, what the signals mean, and what to do when a signal occurs are the first line of defense — and the most valuable source of process knowledge when investigating causes.
Control charts require periodic reassessment. A process that has been improved should have its control limits recalculated to reflect the new baseline. Limits derived from a period of poor performance will be too wide to detect meaningful shifts in the improved process. Plan formal reviews of control limit validity at regular intervals and after significant process changes.
Don’t monitor everything. One of the most common failure modes of ambitious SPC deployments is chart proliferation. Twenty charts that are actively monitored and responded to outperform two hundred charts that nobody looks at. Prioritize the process variables that are most strongly linked to customer-relevant outcomes, that have known histories of problematic variation, or where early detection has the greatest economic value. Start narrow, demonstrate value, and expand deliberately.
What SPC Can't Do
SPC is a powerful discipline, but it operates within defined limits that are worth stating plainly.
It is a detection method, not a prevention method. It tells you when something has changed; it doesn’t prevent the change from happening. Prevention requires process design, mistake-proofing, and robust engineering — SPC is a monitoring layer on top of those foundations, not a substitute for them.
It is also not a root-cause analysis tool. A control chart identifies that a special cause is present. It does not identify what that cause is. The investigation — the 5 Whys, the fishbone analysis, the designed experiment — is separate work that SPC triggers but does not perform.
And it cannot compensate for bad measurement systems. Control limits derived from a measurement system with significant gauge error will be inflated by that error, masking real process variation. Gauge R&R studies — assessing the repeatability and reproducibility of the measurement system — are a prerequisite for credible SPC, not an afterthought.
The Bottom Line
Statistical Process Control is not a new idea. The mathematics are mature, the methods are standardized, and the evidence for their effectiveness when properly implemented spans decades and industries. The reasons SPC programs underperform are almost never about the statistics.
They underperform because control limits are set without proper baseline analysis. Because charts aren’t connected to response protocols. Because high-frequency data is monitored with methods that assume independence. Because capability is assessed before control is achieved. Because too many charts are deployed and too few are owned.
The companies that get sustained value from SPC treat it as a discipline — an ongoing organizational commitment to understanding and reducing variation — rather than a software feature. They invest in the infrastructure to collect clean data, the statistical competence to interpret it correctly, and the operational structures to act on what the data reveals.
That investment compounds. A process that is in control and capable doesn’t just produce better parts — it produces predictable lead times, reliable yields, and the headroom to pursue further improvement. That’s not a quality metric. That’s a competitive position.