Manufacturing plants generate more data today than at any point in history. Most of it never reaches anyone who could act on it. The Unified Namespace is a structural fix to a structural problem — and it may be the most important architectural decision a plant can make.
Walk the floor of almost any manufacturing facility and you will find the same underlying reality beneath the noise and motion: data silos everywhere. A SCADA system that cannot talk to the MES. A historian that exports CSV files into someone’s email every morning. An ERP that receives production counts hours after the shift ends. PLCs from five different vendors, each with its own proprietary protocol and access method.
This is not a technology failure. It is an architectural one. The factory was built layer by layer — OT here, IT there, each system selected for what it could do, not for how it would share what it knew. The result is a fundamentally fragmented data landscape that makes real-time visibility, cross-system analytics, and AI-driven optimization all but impossible to implement at scale.
The Unified Namespace, or UNS, is the architectural pattern that breaks this open.
What a Unified Namespace Actually Is
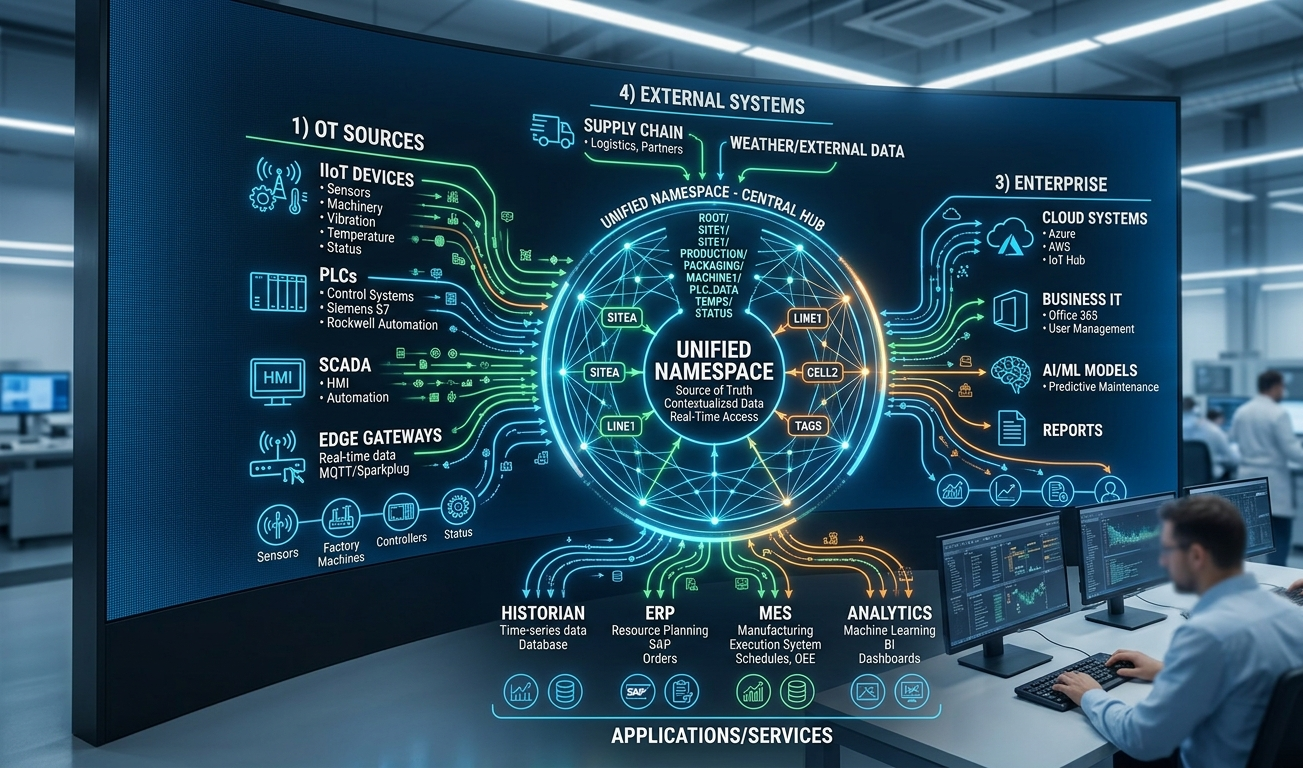
At its core, a UNS is a single, centralized data broker — most commonly built on MQTT — where every system in the plant publishes its data to a shared namespace, and every consumer of that data subscribes to exactly what it needs. No point-to-point integrations. No polling loops. No batch extracts. Just a continuous, structured stream of contextual data flowing through one logical hub.
The “namespace” part matters as much as the “unified” part. Data is organized into a hierarchical topic structure — typically following the ISA-95 enterprise hierarchy: enterprise, site, area, line, cell, device — so that any piece of data can be addressed, discovered, and contextualized without prior coordination between teams.
The crucial distinction from traditional integration approaches is directionality and coupling. In legacy architectures, systems are wired together — A pulls from B, C pushes to D — creating a web of dependencies that makes any change expensive and risky. In a UNS, systems are decoupled. A producer publishes data without knowing or caring who consumes it. A consumer subscribes without needing to know which system generated the data. The broker is the only shared dependency.
Why Traditional Integration Architectures Break Down
Most manufacturing organizations have tried to solve the data integration problem through one of two approaches: point-to-point connections, or a tiered data pipeline (OT to historian to data lake to analytics platform). Both approaches have significant limitations at scale.
Point-to-point integrations — OPC-UA connections, database queries, API calls between systems — work for specific use cases but do not scale. Each new integration is bespoke. When a system is upgraded or replaced, every integration touching it must be rebuilt. Organizations find themselves managing dozens or hundreds of fragile connections, each maintained by a different team.
The tiered pipeline model moves data upward through the ISA-95 stack in batch increments. This introduces latency by design — data that starts in a PLC might take minutes or hours to appear in an analytics dashboard. For use cases like real-time quality monitoring, predictive maintenance triggering, or dynamic scheduling, that latency is disqualifying.
The UNS sidesteps both problems by making data available at the moment of creation, to any authorized subscriber, without pre-wired connections.
The Analytics Implications Are Significant
From a manufacturing analytics perspective, the UNS changes what is possible in fundamental ways. Consider a common scenario: a quality alert fires on Line 3. In a fragmented architecture, correlating that alert with machine sensor data, operator inputs, material lot information, and upstream process parameters requires pulling data from multiple systems on different schedules — often manually. Root cause analysis that should take minutes takes hours, or does not happen at all.
In a UNS-enabled environment, all of that data is already in one namespace, timestamped and contextualized. An analytics layer — whether a BI tool, a Python model, or an AI inference engine — can subscribe to all relevant topics and produce a correlated view in near-real-time. The analytical question does not change; the time and friction to answer it drops dramatically.
This matters particularly for machine learning applications. Models trained on historical data from siloed systems are inevitably limited by what data was collected and how it was joined. A UNS creates a continuous, high-fidelity data stream that is far richer as a training source — and enables models to be served in inference environments with access to live context, not stale snapshots.
Implementation Is a Journey, Not a Project
Organizations that approach UNS implementation as a single large program tend to struggle. The more effective pattern is incremental: start with one area, one line, or one plant — connect the sources that are most valuable for active use cases, prove the pattern works, then expand. The architectural investment pays dividends on every subsequent use case because the data infrastructure already exists.
The technology selection matters less than the architecture. Sparkplug B — an MQTT specification designed specifically for industrial data — has emerged as a strong standard for the OT-side of the UNS, providing consistent payload structure and state management. On the IT side, brokers like HiveMQ, EMQX, and open-source options like Mosquitto are all viable depending on scale and enterprise requirements.
What matters more than tooling is data modeling discipline. The namespace structure must be defined deliberately: how assets are named, how topics are organized, what metadata accompanies each data point. Poor naming and inconsistent structure at the outset become compounding problems as the namespace grows. Organizations that invest in data modeling governance early save significant remediation effort later.
The Organizational Dimension
A UNS is not just a technology implementation — it is a change to how data ownership and access work in a manufacturing organization. In most plants today, OT data is controlled by the OT team, often with significant restrictions on who can access what. The UNS model challenges that paradigm: data becomes a shared resource, with access managed through topic-level permissions rather than system-level gatekeeping.
This requires active leadership engagement. IT and OT teams that have operated independently for decades need a shared governance model for how data is published, contextualized, and consumed. That governance conversation is often harder than the technical implementation — and it is often where UNS initiatives stall.
Organizations that succeed treat UNS adoption as a cross-functional initiative with executive sponsorship, not an IT infrastructure project. They establish clear ownership of the namespace structure, invest in training for both OT and IT teams, and create visible wins quickly to build organizational confidence in the approach.
Where This Points
The Unified Namespace is not a new concept — Walker Reynolds and the industrial data community have been advocating for it for years. What has changed is the urgency. As competitive pressure to implement AI-driven optimization, real-time visibility, and autonomous process control intensifies, organizations without a coherent data architecture find themselves blocked at every turn — not by analytics talent or algorithmic sophistication, but by the inability to get clean, contextual, timely data to the systems that need it.
The UNS does not solve every manufacturing data problem. It does not replace the need for data quality discipline, analytical expertise, or domain knowledge. But it removes the architectural barrier that makes all of those things harder than they need to be — and in doing so, it opens up a category of use cases that are simply not viable without it.
For manufacturing organizations thinking seriously about their analytics roadmap, the question is not whether to build toward a unified namespace. It is how to sequence the journey.